Stories



-
![نبض الملاعب]()
نبض الملاعب
RT STORIES
الادعاء العام في نيويورك يستدعي "الفيفا" للتحقيق في قصة تذاكر مونديال 2026
![الادعاء العام في نيويورك يستدعي "الفيفا" للتحقيق في قصة تذاكر مونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هالاند يوجه رسالة مؤثرة لغوارديولا بعد رحيله عن مانشستر سيتي
![هالاند يوجه رسالة مؤثرة لغوارديولا بعد رحيله عن مانشستر سيتي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لاعبان فقط من الدوري المحلي واستبعاد فريمبونغ وتشافي سيمونز من تشكيلة هولندا لكأس العالم
![لاعبان فقط من الدوري المحلي واستبعاد فريمبونغ وتشافي سيمونز من تشكيلة هولندا لكأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مدرب منتخب الأرجنتين يزف خبرا سارا لمشجعي ميسي قبل انطلاق كأس العالم
![مدرب منتخب الأرجنتين يزف خبرا سارا لمشجعي ميسي قبل انطلاق كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مبابي يتوج بجائزة جديدة مع ريال مدريد (صورة)
![مبابي يتوج بجائزة جديدة مع ريال مدريد (صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إصابة خطيرة تجبر كاسبر شمايكل على اعتزال كرة القدم
![إصابة خطيرة تجبر كاسبر شمايكل على اعتزال كرة القدم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قبل كأس العالم.. لامين جمال يتخذ قرارا هاما
![قبل كأس العالم.. لامين جمال يتخذ قرارا هاما]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رغم العداء التقليدي.. تصريح مثير من فينيسيوس جونيورعن لامين جمال
![رغم العداء التقليدي.. تصريح مثير من فينيسيوس جونيورعن لامين جمال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
صراع الملايين يشتعل.. جوائز كأس عاصمة مصر ترفع سقف المنافسة قبل الحسم
![صراع الملايين يشتعل.. جوائز كأس عاصمة مصر ترفع سقف المنافسة قبل الحسم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الأهلي المصري يتحرك للتعاقد مع خليفة لتوروب
![الأهلي المصري يتحرك للتعاقد مع خليفة لتوروب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وكيل صلاح يفاجئ جماهير ليفربول بصورة مؤثرة
![وكيل صلاح يفاجئ جماهير ليفربول بصورة مؤثرة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المليار الثاني.. ريال مدريد يؤكد زعامته كأغنى ناد في العالم
![المليار الثاني.. ريال مدريد يؤكد زعامته كأغنى ناد في العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فينيسيوس جونيور يعلق على مستقبله مع ريال مدريد (فيديو)
![فينيسيوس جونيور يعلق على مستقبله مع ريال مدريد (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد مسيرة ذهبية.. مودريتش يعلن خطوته الأخيرة
![بعد مسيرة ذهبية.. مودريتش يعلن خطوته الأخيرة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رونالدو يفتح الباب أمام شراكة نارية مع محمد صلاح
![رونالدو يفتح الباب أمام شراكة نارية مع محمد صلاح]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
عرض مفاجئ لزين الدين زيدان من الدوري التركي
![عرض مفاجئ لزين الدين زيدان من الدوري التركي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد رحيله عن ليفربول.. إيان راش يوجه رسالة هامة إلى محمد صلاح (صورة)
![بعد رحيله عن ليفربول.. إيان راش يوجه رسالة هامة إلى محمد صلاح (صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مورينيو يضع شروطه للعودة إلى ريال مدريد
![مورينيو يضع شروطه للعودة إلى ريال مدريد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جيسوس يودع النصر السعودي برسالة مؤثرة (صورة)
![جيسوس يودع النصر السعودي برسالة مؤثرة (صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هل انتهى عصر الهداف في "المانشافت؟.. الرقم 9 يفضح معاناة ألمانيا الهجومية
![هل انتهى عصر الهداف في "المانشافت؟.. الرقم 9 يفضح معاناة ألمانيا الهجومية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
خطوة مفاجئة من يويفا قبل نهائي دوري أبطال أوروبا
![خطوة مفاجئة من يويفا قبل نهائي دوري أبطال أوروبا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![نبض الملاعب]() نبض الملاعب
نبض الملاعب
-
![إسرائيل تواصل غاراتها على لبنان]()
إسرائيل تواصل غاراتها على لبنان
RT STORIES
لبنان.. انتشال عسكري قتل بضربة إسرائيلية استهدفته في البقاع
![لبنان.. انتشال عسكري قتل بضربة إسرائيلية استهدفته في البقاع]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يستهدف أكثر من 150 بنية تحتية تابعة لحزب الله
![الجيش الإسرائيلي يستهدف أكثر من 150 بنية تحتية تابعة لحزب الله]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المصلحة الوطنية لنهر الليطاني ترفع مستوى التحذير إلى أقصى حد بعد استهدافات إسرائيل لمحيط سد القرعون
![المصلحة الوطنية لنهر الليطاني ترفع مستوى التحذير إلى أقصى حد بعد استهدافات إسرائيل لمحيط سد القرعون]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مصادر: اتصالات الرئاسة اللبنانية مع واشنطن نجحت في تحييد بيروت عن الاستهداف الإسرائيلي
![مصادر: اتصالات الرئاسة اللبنانية مع واشنطن نجحت في تحييد بيروت عن الاستهداف الإسرائيلي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
توثيق دراماتيكي لمسيّرة لـ"حزب الله" تتجاوز حراس الأمن في مستوطنة "شوميرا" (فيديو)
![توثيق دراماتيكي لمسيّرة لـ"حزب الله" تتجاوز حراس الأمن في مستوطنة "شوميرا" (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يصدر إنذارات بإخلاء عشرات القرى جنوب لبنان
![الجيش الإسرائيلي يصدر إنذارات بإخلاء عشرات القرى جنوب لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"أحدهم ركض وآخر قفز هاربا".. مشاهد من استهداف "حزب الله" لجنود إسرائيليين بشكل مباشر (فيديو)
!["أحدهم ركض وآخر قفز هاربا".. مشاهد من استهداف "حزب الله" لجنود إسرائيليين بشكل مباشر (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان..31 قتيلا وعشرات الجرحى في غارات إسرائيلية وإنذارات تهجير تطال 47 بلدة
![لبنان..31 قتيلا وعشرات الجرحى في غارات إسرائيلية وإنذارات تهجير تطال 47 بلدة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
معارك ضارية مع الجيش الإسرائيلي في جنوب لبنان و"حزب الله" ينفذ 32 عملية عسكرية نوعية في يوم واحد فقط
![معارك ضارية مع الجيش الإسرائيلي في جنوب لبنان و"حزب الله" ينفذ 32 عملية عسكرية نوعية في يوم واحد فقط]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فيديو "مطاردة المسيرة" يهز إسرائيل.. هل فقدت تل أبيب السيطرة على جبهة الشمال بشكل كامل؟
![فيديو "مطاردة المسيرة" يهز إسرائيل.. هل فقدت تل أبيب السيطرة على جبهة الشمال بشكل كامل؟]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![إسرائيل تواصل غاراتها على لبنان]() إسرائيل تواصل غاراتها على لبنان
إسرائيل تواصل غاراتها على لبنان
-
![فيديوهات]()
فيديوهات
RT STORIES
روسيا.. إعصار قوي وعاصفة ترابية في مقاطعة تشيليابينسك
![روسيا.. إعصار قوي وعاصفة ترابية في مقاطعة تشيليابينسك]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المكسيك.. إعصار يضرب المناطق الشمالية دون أضرار
![المكسيك.. إعصار يضرب المناطق الشمالية دون أضرار]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
"بانتسير-اس" تحمي المجال الجوي من صواريخ العدو
!["بانتسير-اس" تحمي المجال الجوي من صواريخ العدو]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مشاهد لمعارك تحرير القوات الروسية لبلدة غرانوف في مقاطعة خاركوف
![مشاهد لمعارك تحرير القوات الروسية لبلدة غرانوف في مقاطعة خاركوف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية تعلن تحرير بلدتين جديدتين جنوب وشرق أوكرانيا
![الدفاع الروسية تعلن تحرير بلدتين جديدتين جنوب وشرق أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
خبير إيرالندي يحذر الأوروبيين من تجاهل التحذير الروسي
![خبير إيرالندي يحذر الأوروبيين من تجاهل التحذير الروسي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مصادر ميدانية: القيادة العسكرية الأوكرانية تأمر بقصف قواتها لمنع انسحابها
![مصادر ميدانية: القيادة العسكرية الأوكرانية تأمر بقصف قواتها لمنع انسحابها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هجوم أوكراني على مدينة سيفاستوبول في القرم بالصواريخ والمسيرات
![هجوم أوكراني على مدينة سيفاستوبول في القرم بالصواريخ والمسيرات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
زاخاروفا: اختلاق استفزاز بوتشا جاء لتعطيل المفاوضات بين روسيا وأوكرانيا
![زاخاروفا: اختلاق استفزاز بوتشا جاء لتعطيل المفاوضات بين روسيا وأوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: إسقاط 6 مسيرات أوكرانية فوق بيلغورود والقرم وبحر آزوف
![الدفاع الروسية: إسقاط 6 مسيرات أوكرانية فوق بيلغورود والقرم وبحر آزوف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نيبينزيا: ترامب يريد تسوية في أوكرانيا لكن يجب معالجة الأسباب الجذرية
![نيبينزيا: ترامب يريد تسوية في أوكرانيا لكن يجب معالجة الأسباب الجذرية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوليانسكي: الغرب غير مهتم بحل النزاع في أوكرانيا
![بوليانسكي: الغرب غير مهتم بحل النزاع في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بولندا ترفض إجلاء سفارتها من كييف رغم التحذيرات الروسية
![بولندا ترفض إجلاء سفارتها من كييف رغم التحذيرات الروسية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![هدنة وحصار المضيق]()
هدنة وحصار المضيق
RT STORIES
وزارة الأمن الإيرانية تؤكد تحول المعركة ضدها إلى الظل وتكشف عن بنودها السبعة
![وزارة الأمن الإيرانية تؤكد تحول المعركة ضدها إلى الظل وتكشف عن بنودها السبعة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فانس: متفائل بموافقة إيران على أي اتفاق يمنع تطويرها أسلحة نووية
![فانس: متفائل بموافقة إيران على أي اتفاق يمنع تطويرها أسلحة نووية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الأمريكي: "مشروع الحرية" لم يستأنف عمله ولا نقوم حاليا بمرافقة السفن التجارية عبر مضيق هرمز
![الجيش الأمريكي: "مشروع الحرية" لم يستأنف عمله ولا نقوم حاليا بمرافقة السفن التجارية عبر مضيق هرمز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نيبينزيا: روسيا مستعدة لاستقبال اليورانيوم المخصب من إيران
![نيبينزيا: روسيا مستعدة لاستقبال اليورانيوم المخصب من إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الصين: أي اتفاق بين الولايات المتحدة وإيران يجب أن يُعرض على مجلس الأمن لمنحه الشرعية
![الصين: أي اتفاق بين الولايات المتحدة وإيران يجب أن يُعرض على مجلس الأمن لمنحه الشرعية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
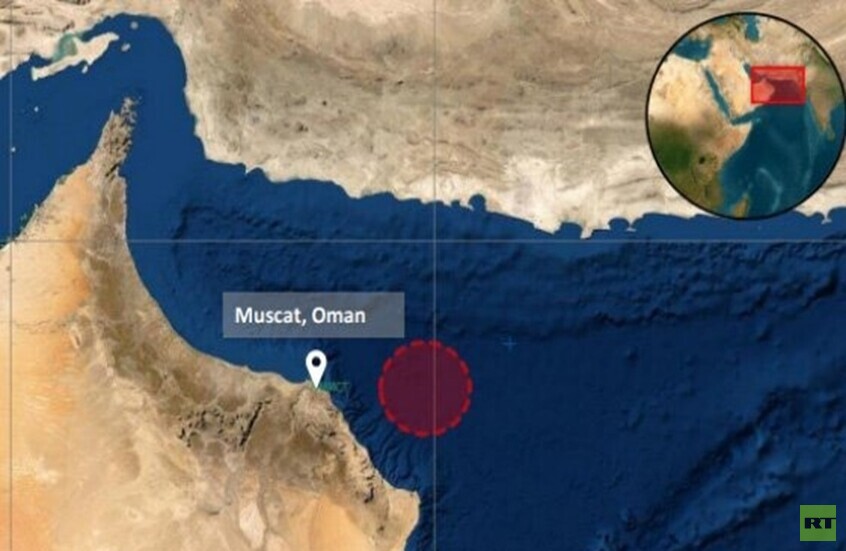
انفجار خارجي يضرب ناقلة نفط قبالة سواحل عمان ويتسبب بتسرب وقود
![انفجار خارجي يضرب ناقلة نفط قبالة سواحل عمان ويتسبب بتسرب وقود]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![هدنة وحصار المضيق]() هدنة وحصار المضيق
هدنة وحصار المضيق
-
![عيد الأضحى المبارك]()
عيد الأضحى المبارك
RT STORIES
ملك الأردن وولي عهده يشاركان المصلين أداء صلاة عيد الأضحى في العقبة (صور+فيديو )
![ملك الأردن وولي عهده يشاركان المصلين أداء صلاة عيد الأضحى في العقبة (صور+فيديو )]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حقائب "باليستية" تحيط بأحمد الشرع خلال صلاة العيد في حلب (فيديو)
![حقائب "باليستية" تحيط بأحمد الشرع خلال صلاة العيد في حلب (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أمير قطر يؤدي صلاة العيد في مصلى لوسيل (فيديو)
![أمير قطر يؤدي صلاة العيد في مصلى لوسيل (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أهالي غزة يؤدون صلاة الأضحى بين الأنقاض (فيديو+صور)
![أهالي غزة يؤدون صلاة الأضحى بين الأنقاض (فيديو+صور)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيس الإدارة الدينية لمسلمي روسيا: الأضحى نقطة انطلاق لتعزيز القيم الإنسانية والسلام العالمي
![رئيس الإدارة الدينية لمسلمي روسيا: الأضحى نقطة انطلاق لتعزيز القيم الإنسانية والسلام العالمي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المسلمون يؤدون صلاة عيد الأضحى في مسجد موسكو الكبير (فيديو+صور)
![المسلمون يؤدون صلاة عيد الأضحى في مسجد موسكو الكبير (فيديو+صور)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كربلاء تشهد أضخم تجمع لصلاة عيد الأضحى (فيديو)
![كربلاء تشهد أضخم تجمع لصلاة عيد الأضحى (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بوتين يهنئ مسلمي روسيا بعيد الأضحى المبارك
![بوتين يهنئ مسلمي روسيا بعيد الأضحى المبارك]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مصر.. السيسي يؤدي صلاة عيد الأضحى ويتبادل التهاني (فيديو)
![مصر.. السيسي يؤدي صلاة عيد الأضحى ويتبادل التهاني (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الرئيس السوري يؤدي صلاة عيد الأضحى في مسجد عبد الله بن عباس بمدينة حلب (فيديو)
![الرئيس السوري يؤدي صلاة عيد الأضحى في مسجد عبد الله بن عباس بمدينة حلب (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![عيد الأضحى المبارك]() عيد الأضحى المبارك
عيد الأضحى المبارك
-
![عيد الأضحى يجمع العرب في ساحات الصلاة.. وفلسطين حاضرة بين الركام والقيود (فيديو)]()
عيد الأضحى يجمع العرب في ساحات الصلاة.. وفلسطين حاضرة بين الركام والقيود (فيديو)
RT STORIES
عيد الأضحى يجمع العرب في ساحات الصلاة.. وفلسطين حاضرة بين الركام والقيود (فيديو)
![عيد الأضحى يجمع العرب في ساحات الصلاة.. وفلسطين حاضرة بين الركام والقيود (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More
































































مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

فأي إجابة يقدمها، سواء كانت مبنية على استدلال مدروس أو مجرد تخمين، يطرحها بالقدر نفسه من الثقة.
واكتشف باحثون في مختبر علوم الحاسوب والذكاء الاصطناعي بمعهد ماساتشوستس للتكنولوجيا أن أصل هذه الثقة المفرطة يعود إلى خلل محدد في طريقة تدريب النماذج، وقد طوروا أسلوبا جديدا يهدف إلى معالجة هذا الخلل دون التأثير على دقة الأداء.
وتُعرف هذه الطريقة باسم RLCR (التعلم المعزز باستخدام مكافآت المعايرة)، وقد وُصفت في بحث منشور على منصة arXiv، ومن المقرر تقديمه في المؤتمر الدولي للتعلم الآلي ICLR 2026 في ريو دي جانيرو. وتعتمد هذه المنهجية على تدريب النماذج اللغوية على تقديم إجابات مرفقة بتقدير لدرجة الثقة، أي أن النموذج لا يكتفي بالإجابة، بل يعبّر أيضا عن مستوى عدم يقينه.

ميتا تطلق أداة جديدة تتيح للآباء مراقبة محادثات أطفالهم مع الذكاء الاصطناعي
ما المشكلة؟
تقوم أساليب التعلم المعزز المستخدمة في أحدث نماذج التفكير الاصطناعي على مكافأة الإجابة الصحيحة ومعاقبة الإجابة الخاطئة، دون التمييز بين طريقة الوصول إلى النتيجة. وبالتالي، يحصل النموذج الذي يصل إلى الإجابة الصحيحة عبر استنتاج منطقي، على نفس المكافأة التي يحصل عليها نموذج آخر وصل إليها عن طريق التخمين.
ومع مرور الوقت، يؤدي ذلك إلى ترسيخ سلوك لدى النماذج يجعلها تميل إلى تقديم إجابات واثقة حتى في الحالات التي تفتقر فيها إلى الأدلة الكافية.
وتترتب على هذه الثقة المفرطة آثار سلبية، خاصة عند استخدام هذه النماذج في مجالات حساسة مثل الطب أو القانون أو التمويل، حيث تعتمد القرارات البشرية على مخرجات الذكاء الاصطناعي. فالنموذج الذي يعبر عن ثقة عالية غير دقيقة قد يكون أكثر خطورة من نموذج يخطئ بوضوح، لأن المستخدم قد لا يدرك ضرورة التحقق من الإجابة.
ويشرح طالب الدراسات العليا في معهد ماساتشوستس للتكنولوجيا وأحد مؤلفي الدراسة، ميهول داماني، قائلا:
"إن أساليب التدريب التقليدية بسيطة وفعالة، لكنها لا تشجع النموذج على التعبير عن عدم اليقين أو قول (لا أعرف)، لذلك يتعلم النموذج بطبيعته أن يخمّن عندما لا يكون واثقا".
ما الحل؟
تعالج طريقة RLCR هذه المشكلة بإضافة عنصر واحد إلى دالة المكافأة، وهو مقياس "براير" (Brier score)، المستخدم لقياس مدى تطابق ثقة النموذج مع دقته الفعلية. خلال التدريب، تتعلم النماذج تقييم كل من الإجابة وعدم يقينها في الوقت نفسه، بحيث تقدم الجواب مع تقدير لمستوى الثقة.
وبذلك تتم معاقبة كل من الإجابات الخاطئة ذات الثقة المبالغ فيها، والإجابات الصحيحة المصحوبة بعدم ثقة غير مبررة، مما يساعد على تحقيق توازن أفضل بين الدقة والتعبير الواقعي عن الثقة.
المصدر: Naukatv.ru
إقرأ المزيد

OpenAI تحل لغز الهوس الغريب لتطبيق ChatGPT بالمخلوق اﻷسطوري "غولبن"
تمكنت شركة OpenAI من حل لغز تسبب في تحول روبوت الدردشة الشهير ChatGPT إلى كائن مهووس بالمخلوقات الأسطورية، وخصوصا "الغولبن" (goblins).

لا أثق به ثقة عمياء.. مدفيديف يتحدث عن التحدي الأكبر في مواجهة الذكاء الاصطناعي
كشف نائب رئيس مجلس الأمن الروسي دميتري مدفيديف أنه يستخدم برمجيات الذكاء الاصطناعي في عمله اليومي، لكنه لا يثق بها ثقة عمياء.

DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

عطل أم تصرف عدواني؟.. روبوت يفلت من السيطرة في مهرجان صيني (فيديو)
أثارت حادثة غريبة خلال مهرجان في الصين جدلا كبيرا حول سلامة الروبوتات المتقدمة، بعد أن ظهر روبوت شبيه بالإنسان وهو يتحرك بشكل غير متوقع، ما أثار صدمة الحاضرين.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.



























































































التعليقات